
This technical insight article explores the inner workings of Apache Kafka, an open-source distributed streaming platform which revolutionises real-time data pipelines and streaming applications.
At Pretty Technical we use Kafka across a variety of applications, including our Domino Data Vault and Mikado our Player Account Management system (PAM). It’s a crucial element in our microservices oriented architecture due to its ability to process information from multiple sources simultaneously in real-time in a reliable and easy to implement way. We also use some of its extensions such as Zookeeper and Kowl to optimise its benefits.
Apache Kafka operates as a distributed publish-subscribe messaging system, facilitating the publication and subscription to real-time or near-real-time data feeds. Its high throughput, scalability, durability, fault tolerance, and ecosystem of robust features make it ideal for various use cases.
Key Kafka Components
Apache Kafka’s robust and scalable architecture is achieved through the seamless interaction of Producers, Consumers, Brokers, Topics, and Partitions. This makes it the preferred choice for organisations navigating the complexities of real-time data processing. Let’s take a closer look at the common components of Kafka Architecture:
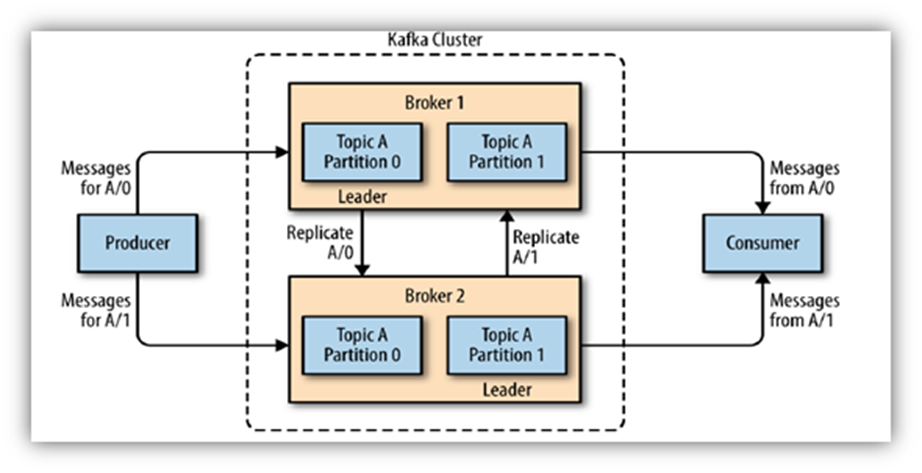
Producer – Publishing Data Streams:
Producers within the Kafka ecosystem play a vital role in initiating the flow of data. They are responsible for publishing messages to Kafka topics, which can be seen as channels or feeds where data is categorised and organised. Producers ensure a continuous stream of data, making them instrumental in feeding real-time information into the Kafka ecosystem.
Consumer – Subscription and Processing:
Consumers are the counterpart to Producers, subscribing to specific Kafka topics to access the published messages. Once subscribed, Consumers process the incoming stream of data, enabling various applications and systems to react to, analyse, or store the information. This makes Consumers an integral part of real-time data processing architectures.
Broker – Data Storage and Cluster Formation: Brokers form the backbone of the Kafka architecture. They act as servers dedicated to storing and serving data, forming clusters to enhance performance, reliability, and fault tolerance. Brokers ensure the seamless flow of data within the Kafka ecosystem by managing the communication between Producers and Consumers. Their role in clustering is vital for scalability, enabling Kafka to efficiently handle large volumes of data.
Topic – Message Categorisation:
Topics serve as the organisational backbone of Kafka, representing message categories to which Producers publish data. Acting as channels for data streams, Topics enable the logical categorisation and segregation of information. This ensures that data can be efficiently managed, analysed, and consumed by the relevant Consumers.
Partition – Enhancing Scalability and Parallelism:
Within each Topic, messages are further organised into Partitions, enhancing parallelism and scalability, enabling Kafka to efficiently handle high-throughput data streams. Partitions allow multiple Consumers to simultaneously process different partitions ensuring that the processing load is distributed for optimal performance. As data is distributed across multiple nodes within the Kafka cluster, Partitioning also contributes to fault tolerance.
Common Use Cases of Kafka:
Kafka’s versatile applications make it ideal for use in a number of diverse scenarios:
Aggregating Data from Different Sources:
Kafka serves as a central hub for ingesting, organising, transforming, and distributing data from a myriad of sources. This functionality is crucial for organisations implementing Extract, Transform, Load (ETL) pipelines, establishing and maintaining data lakes and efficiently delivering comprehensive log aggregation.
Real-time Analytics:
Organisations can build robust applications that enable instantaneous data analysis for real-time reporting, dashboards, or complex analytics using Kafka. Its ability to handle high-throughput data streams ensures that insights are delivered in real-time, empowering businesses to make timely and informed decisions.
Event Processing: Kafka plays a pivotal role in powering systems that rely on real-time event processing. This makes it an ideal solution for emerging technologies like Internet of Things (IoT) devices. Kafka enables responsive and adaptive systems by seamlessly handling the constant flow of events generated by IoT devices.
Monitoring and Logging:
Kafka excels in storing and managing logs and metrics, providing a real-time data-based foundation for monitoring and alerts. This capability is instrumental in maintaining the health and performance of applications and infrastructure. Kafka can help to proactively identify issues, monitor key metrics, and set up alerts to respond promptly to any deviations from expected norms.
Conclusion:
While Kafka offers advantages like fault tolerance, high throughput, durability, and scalability, it introduces complexity to system architecture. Despite this, its popularity persists, especially when a real-time data feed is crucial.
Kafka is a versatile and indispensable tool for organisations seeking to harness the power of real-time data across a spectrum of applications and use cases. Whether it’s optimising data workflows, enabling rapid analytics, facilitating event-driven architectures, or ensuring vigilant monitoring, Kafka drives efficiency and innovation in the ever-evolving data management and processing landscape.
Apache Kafka stands as a robust solution for organisations navigating the complexities of real-time data processing. Whether powering analytics, event processing, or monitoring, Kafka’s versatility and performance make it a frontrunner in the realm of distributed streaming platforms.
To learn more about how to unlock the potential of Apache Kafka for your organisation’s real-time data needs, please email us at [email protected].

